La progettazione di un data model efficace è il cuore di ogni progetto di analisi: in Power BI, in particolare, rappresenta le fondamenta su cui costruire uno sviluppo fluido, efficiente e manutenibile. Un modello ben strutturato permette di trasformare dati grezzi in insight utili, facilitando l’identificazione di pattern significativi e il supporto a decisioni data-driven. Al contrario, un modello confuso o disorganizzato può compromettere le performance, generare analisi fuorvianti e complicare la gestione futura del progetto.
In questo articolo analizzeremo gli errori più comuni nella modellazione dei dati in Power BI, con l’obiettivo di aiutarti a costruire modelli semplici, robusti, coerenti e scalabili. Evitarli è il primo passo per fare del tuo data model una risorsa strategica, non un ostacolo.
Power BI: i 5 errori comuni nella modellazione dati e come evitarli
1. Eseguire trasformazioni massive con Power Qwery (o peggio) DAX anziché sul database sorgente quando possibile
Un errore frequente nella progettazione di modelli in Power BI è l’uso di Power Query – e, ancor più, di DAX – per eseguire trasformazioni massive dei dati che potrebbero essere gestite direttamente nel database sorgente. Trasformare, ad esempio, una grande quantità di dati di vendita in Power BI con colonne calcolate in DAX significa che, ad ogni aggiornamento, il sistema deve elaborare queste trasformazioni, consumando risorse preziose – è come trasportare mattoni uno per uno invece di usare un carrello elevatore.
I database moderni dispongono di algoritmi ottimizzati e strutture specializzate per queste operazioni, mentre Power BI è concepito principalmente per la visualizzazione e l’analisi. La regola d’oro è quindi di eseguire le trasformazioni complesse alla fonte. Se ciò non è possibile, utilizzare custom query in Power Query e ricorrere a DAX solo in ultima istanza. In questo modo, si sfruttano DAX e Power Query per i loro scopi principali – rispettivamente per calcoli analitici e logica di business, e per operazioni non realizzabili direttamente alla sorgente – evitando di penalizzare le prestazioni del modello.
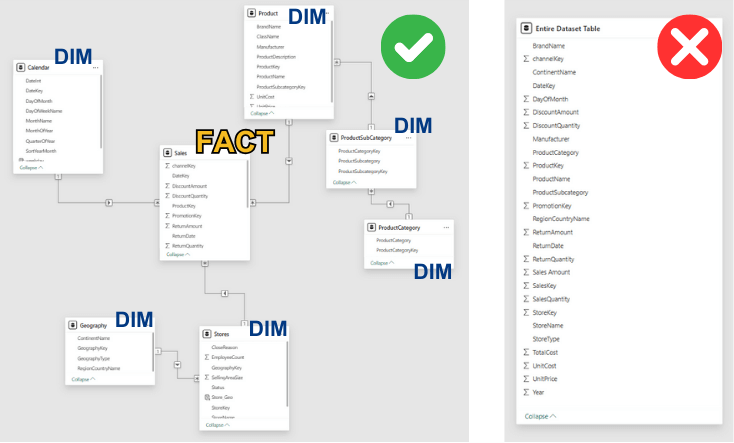
2. Lavorare con un’unica tabella che contiene tutti i dati (dataset non normalizzato)
La normalizzazione dei dati è essenziale per creare modelli analitici efficaci in Power BI, anche se spesso viene trascurata. Immagina una biblioteca in cui tutti i libri sono ammassati in un unico scaffale senza ordine: così risulta un modello non normalizzato, in cui dati di clienti, ordini e prodotti sono confusi in un’unica tabella. Questo approccio porta a duplicazioni, inconsistenze e analisi complicate, perché ogni modifica (ad esempio l’aggiornamento di un indirizzo cliente) deve essere ripetuta in molteplici punti.
La normalizzazione consiste nell’organizzare i dati in tabelle separate e correlate, ognuna con uno scopo specifico. È come suddividere un armadio in scomparti ben definiti, in modo da trovare facilmente ciò che serve. Per esempio, la prima forma normale richiede che ogni cella contenga un solo valore: se in una colonna “Città” sono elencate più città insieme, va invece creata una riga per ogni città. La seconda forma normale sottolinea l’importanza delle chiavi, elementi identificativi unici (come un ID_Prodotto) che collegano le tabelle, assicurando che ogni informazione dipenda interamente dalla chiave corretta.
In Power BI, un modello normalizzato si traduce in strutture come lo star schema o lo snowflake, dove una tabella dei fatti centrale è collegata a tabelle dimensionali chiare e distinte. Questo approccio non solo migliora le performance, ma rende anche il modello più intuitivo per gli utenti finali.
Investire tempo nella normalizzazione, sebbene inizialmente richieda più sforzo, porta a una gestione dei dati più efficiente e a un’analisi più accurata nel lungo termine.
3. Modellare i dati senza considerare i requirements
Progettare un modello dati senza comprendere le reali esigenze di business è un errore critico. Prima di iniziare lo sviluppo in Power BI, è essenziale:
- Identificare le domande chiave a cui si vuole rispondere con l’ananlisi
- Definire il livello di dettaglio necessario delle analisi (granularità)
- Mappare gli utenti finali e i loro casi d’uso
Per esempio, se il marketing necessita di analisi per fasce orarie ma raccogliamo solo date, il modello sarà inadeguato nonostante sia tecnicamente corretto.
Nel processo di sviluppo:
- Documenta i requisiti
- Verifica disponibilità e qualità dei dati
- Progetta partendo dai requisiti, non dai dati
- Valida con gli utenti
- Itera basandoti sui feedback
Ogni elemento del modello – tabelle, relazioni, metriche – deve rispondere a un requisito specifico, come un vestito su misura. Solo così il risultato sarà realmente utile al business.
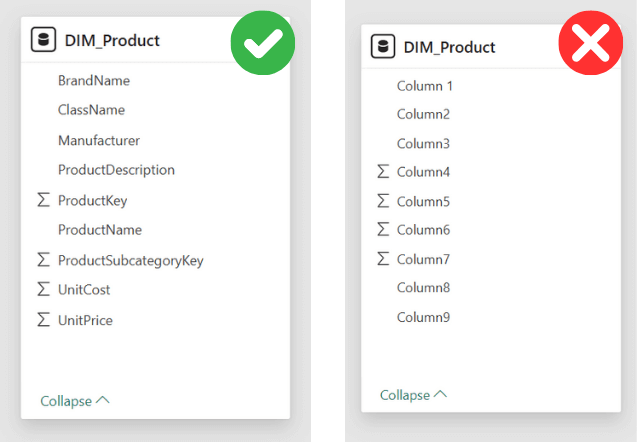
4. Utilizzare nomi poco descrittivi e strutture di schema disordinate
Utilizzare nomi generici o poco descrittivi per tabelle e colonne è un errore che può compromettere seriamente la chiarezza e la manutenibilità di un modello Power BI. Ad esempio, denominare una tabella “Table1” o “FactX” anziché “Vendite2023” non fornisce alcuna informazione immediata sul contenuto dei dati, rendendo difficile per chiunque debba interagire con il modello identificare rapidamente l’origine e la natura delle informazioni.
Questa mancanza di chiarezza diventa ancora più problematica quando si ha a che fare con strutture dati complesse, in cui sono presenti più tabelle dei fatti senza una separazione logica ben definita. L’uso eccessivo di più tabelle dei fatti può creare ambiguità, errori e rendere il modello difficile da gestire. In alcuni casi, tuttavia, più fact table sono utili, come nell’analisi di un e-commerce, dove una tabella registra gli accessi al sito e un’altra gli ordini effettuati.
La chiave è distinguere quando è necessario mantenere più tabelle separate e quando, invece, è preferibile unirle.
Situazioni in cui più Fact Table sono utili:
- Quando rappresentano eventi distinti con granularità diverse (es. login vs acquisti).
- Quando non esiste un chiaro collegamento tra le misure delle due tabelle.
- Quando la combinazione in un’unica tabella genererebbe dati ridondanti o incoerenti.
Casi in cui è meglio unire le Fact Table
- Quando entrambe contengono dati direttamente correlati con la stessa granularità.
- Quando condividono molte dimensioni e le analisi richiedono spesso il confronto tra le loro misure.
- Se mantenere tabelle separate complica inutilmente il modello.
Quando escludere una Fact Table
- Se i dati in essa contenuti non aggiungono valore all’analisi.
Per affrontare questo problema, è fondamentale adottare delle naming convention precise, ovvero regole condivise per assegnare nomi chiari e coerenti a tabelle e colonne. Una buona prassi è quella di scegliere denominazioni che riflettano in modo esplicito il contenuto o la funzione dei dati, facilitando così la comprensione sia per gli sviluppatori che per gli utenti finali. Inoltre, è consigliabile strutturare il modello seguendo il principio dello star schema. Questo approccio prevede l’uso di una singola tabella dei fatti centrale, che contiene le misurazioni, collegata a diverse tabelle di dimensioni che descrivono gli attributi contestuali (come date, prodotti o clienti). Tale organizzazione non solo semplifica le relazioni tra le tabelle, ma rende anche l’analisi dei dati più intuitiva e performante.
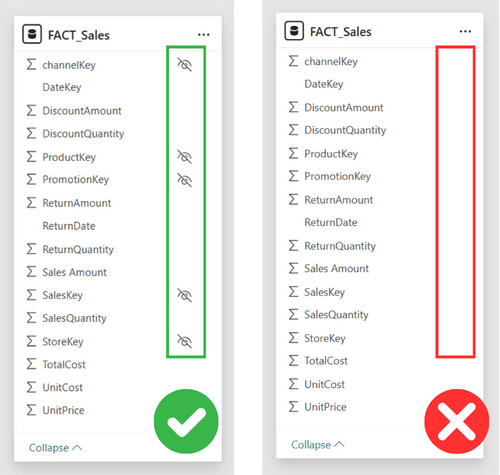
5. Lasciare visibili colonne e tabelle non rilevanti per l’utente finale
Nell’ambito della BI self-service, cioè quando l’utente finale utilizza il modello per analizzare i dati, è fondamentale mostrare solo le informazioni rilevanti. Lasciare visibili colonne e tabelle tecniche (come indici, chiavi, tabelle bridge o junk dimensions) può creare confusione e portare a errori, perché l’utente si troverebbe davanti a dettagli non necessari per la sua analisi. Ad esempio, se in un report appaiono tabelle con chiavi primarie e indici, l’utente potrebbe selezionare campi sbagliati o interpretare erroneamente i dati, complicando la creazione di visualizzazioni efficaci. Pur essendo queste tabelle essenziali per mantenere l’integrità dei dati a livello di modello, non hanno un significato diretto per chi utilizza i report in self-service BI. Pertanto, è consigliabile nascondere questi elementi tramite le funzionalità di Power BI, in modo da offrire un’interfaccia più pulita e focalizzata sulle informazioni analitiche utili, semplificando la navigazione del modello e garantendo che l’utente finale possa concentrarsi esclusivamente sui dati significativi.
Scopri tutte le nostre soluzioni Power BI
Al tuo fianco dalla consulenza alla formazione a soluzioni di data visualization.
Visualitics Team
Questo articolo è stato scritto e redatto da uno dei nostri consulenti.
Condividi ora sui tuoi canali social o via email: