Scikit-learn è una delle librerie più utilizzate per il Machine Learning (apprendimento automatico) in Python. Fondata sulla libreria NumPy, SciPy e Matplotlib, Scikit-learn offre strumenti semplici ed efficienti per l’analisi e la modellazione dei dati. La sua semplicità e versatilità la rendono una scelta popolare sia per i ricercatori, sia per gli sviluppatori che lavorano su progetti di intelligenza artificiale (AI).
Scikit-learn e l'Intelligenza Artificiale in Python
L’Intelligenza Artificiale è un campo dell’informatica che si occupa di creare macchine in grado di svolgere compiti che, solitamente, richiederebbero l’intelligenza umana. L’apprendimento automatico, una sottocategoria dell’AI, permette ai computer di apprendere dai dati e migliorare le loro prestazioni nel tempo senza essere esplicitamente programmati per ogni compito specifico.
Scikit-learn si inserisce perfettamente in questo contesto fornendo una vasta gamma di algoritmi di apprendimento automatico per classificazione, regressione, clustering e riduzione della dimensionalità. Questi strumenti permettono di sviluppare modelli che possono, ad esempio, classificare email come spam o non spam, prevedere prezzi di case, raggruppare clienti in segmenti di mercato simili e molto altro.
Vediamo insieme due applicazioni pratiche di Scikit-learn.
Classificazione con K-Nearest Neighbors (KNN)
Per illustrare come utilizzare Scikit-learn, vediamo un esempio di classificazione utilizzando l’algoritmo K-Nearest Neighbors (KNN). Il KNN è un algoritmo semplice ma potente che classifica un dato punto in base ai punti più vicini nel dataset di addestramento. Nell’esempio riportato, utilizziamo il famoso dataset Iris, che contiene tre diverse specie di iris con quattro caratteristiche ciascuna.
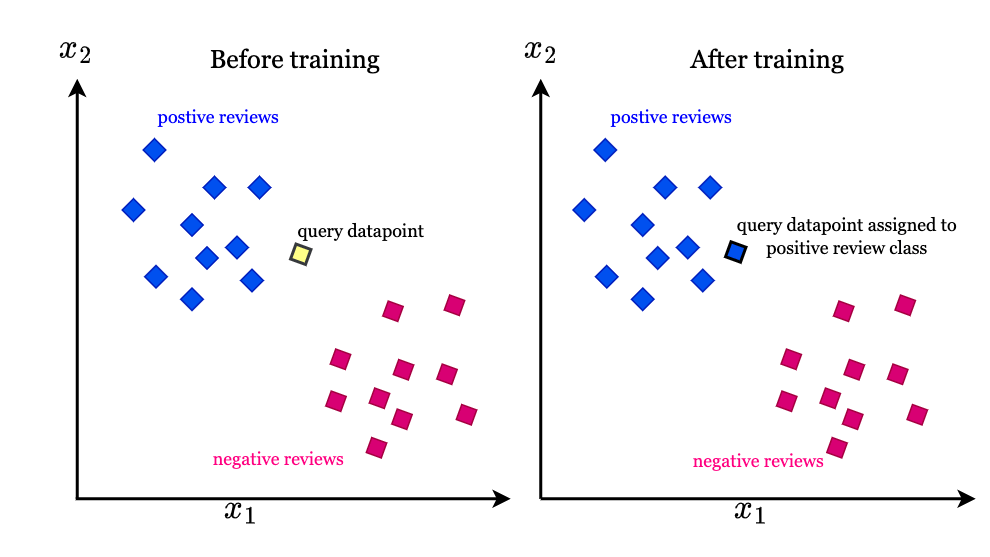
Il codice sottostante mostra come caricare il dataset, suddividerlo in set di addestramento e test, creare un modello KNN, addestrarlo e fare previsioni sui dati di test. Infine, viene calcolata l’accuratezza del modello, che rappresenta la proporzione di previsioni corrette.
from sklearn.datasets import load_iris
from sklearn.model_selection import train_test_split
from sklearn.neighbors import KNeighborsClassifier
from sklearn.metrics import accuracy_score
# Caricamento del dataset Iris
iris = load_iris()
X = iris.data
y = iris.target
# Suddivisione del dataset in training set e test set
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.3, random_state=42)
# Creazione del modello KNN
knn = KNeighborsClassifier(n_neighbors=3)
# Addestramento del modello
knn.fit(X_train, y_train)
# Predizione sul test set
y_pred = knn.predict(X_test)
# Valutazione del modello
accuracy = accuracy_score(y_test, y_pred)
print(f'Accuracy: {accuracy}')
Regressione con Linear Regression
La regressione è un’altra importante area del machine learning. L’algoritmo di regressione lineare è utilizzato per prevedere un valore continuo, come il prezzo di una casa. In questo esempio, utilizziamo il dataset Boston Housing, che contiene informazioni su case in diverse aree di Boston.

Il codice sottostante dimostra come caricare il dataset, suddividerlo in set di addestramento e test, creare un modello di regressione lineare, addestrarlo e fare previsioni. La performance del modello viene valutata utilizzando l’errore quadratico medio (MSE), che misura la differenza media quadratica tra i valori previsti e i valori effettivi.
from sklearn.datasets import load_boston
from sklearn.model_selection import train_test_split
from sklearn.linear_model import LinearRegression
from sklearn.metrics import mean_squared_error
# Caricamento del dataset Boston Housing
boston = load_boston()
X = boston.data
y = boston.target
# Suddivisione del dataset in training set e test set
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.3, random_state=42)
# Creazione del modello Linear Regression
lr = LinearRegression()
# Addestramento del modello
lr.fit(X_train, y_train)
# Predizione sul test set
y_pred = lr.predict(X_test)
# Valutazione del modello
mse = mean_squared_error(y_test, y_pred)
print(f'Mean Squared Error: {mse}')
Conclusioni
Scikit-learn rappresenta uno strumento potente e flessibile per sviluppare soluzioni di apprendimento automatico. La sua facilità d’uso e l’ampia gamma di funzionalità la rendono ideale per una vasta gamma di applicazioni nel campo dell’intelligenza artificiale. Che si tratti di classificazione, regressione, clustering o riduzione della dimensionalità, Scikit-learn fornisce gli strumenti necessari per creare modelli efficaci e performanti.
In sintesi, Scikit-learn è una libreria essenziale per chiunque voglia entrare nel mondo del machine learning e dell’intelligenza artificiale, grazie alla sua semplicità, versatilità e robustezza.
Leggi tutti i nostri articoli sulla Data Tech
Vuoi scopri le ultime novità su Fivetran e nuove tecnologie di data science?

Visualitics Team
Questo articolo è stato scritto e redatto da uno dei nostri consulenti.
Condividi ora sui tuoi canali social o via email: